

Les modèles d'IA ont prouvé leur capacité à accomplir de nombreuses tâches, mais quelles tâches voulons-nous vraiment qu'ils accomplissent ? De préférence des tâches fastidieuses, et il y en a beaucoup dans la recherche et le milieu universitaire. Reliant espère se spécialiser dans le type de travail d'extraction de données chronophage qui est actuellement la spécialité des étudiants diplômés et des stagiaires fatigués.
« La meilleure chose que l’on puisse faire avec l’IA, c’est améliorer l’expérience humaine : réduire le travail subalterne et laisser les gens faire les choses qui sont importantes pour eux », a déclaré le PDG Karl Moritz. Dans le monde de la recherche, où lui et les cofondateurs Marc Bellemare et Richard Schlegel travaillent depuis des années, l’analyse de la littérature est l’un des exemples les plus courants de ce « travail subalterne ».
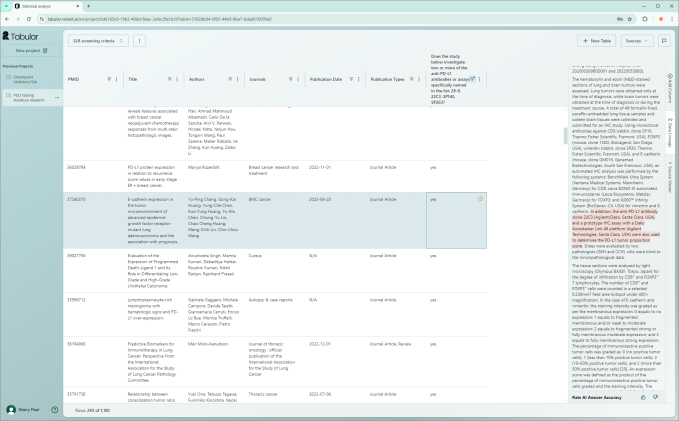
Chaque article cite des travaux antérieurs et connexes, mais trouver ces sources dans la mer de la science n'est pas chose aisée. Et certains, comme les revues systématiques, citent ou utilisent des données provenant de milliers d'ouvrages.
Pour une étude, se souvient Moritz, « les auteurs ont dû examiner 3 500 publications scientifiques, et beaucoup d’entre elles se sont révélées non pertinentes. Cela représente un temps considérable pour extraire une quantité infime d’informations utiles – et cela m’a semblé être quelque chose qui aurait vraiment dû être automatisé par l’IA. »
Ils savaient que les modèles de langage modernes pouvaient le faire : une expérience a confié à ChatGPT cette tâche et a révélé qu'il était capable d'extraire des données avec un taux d'erreur de 11 %. Comme beaucoup de choses que les LLM peuvent faire, c'est impressionnant mais rien à voir avec ce dont les gens ont réellement besoin.
« Ce n’est pas suffisant », a déclaré Moritz. « Pour ces tâches de connaissance, aussi subalternes soient-elles, il est très important de ne pas faire d’erreurs. »
Le produit phare de Reliant, Tabular, est basé en partie sur un LLM (LLaMa 3.1), mais augmenté d'autres techniques propriétaires, il est considérablement plus efficace. Sur l'extraction de plusieurs milliers d'études ci-dessus, ils ont déclaré qu'il a effectué la même tâche sans aucune erreur.
Cela signifie que vous entrez un millier de documents, que vous voulez en extraire telle ou telle donnée, et Reliant les examine attentivement et trouve ces informations, qu'elles soient parfaitement étiquetées et structurées ou (ce qui est beaucoup plus probable) qu'elles ne le soient pas. Il rassemble ensuite toutes ces données et toutes les analyses que vous souhaitiez effectuer dans une interface utilisateur agréable afin que vous puissiez vous plonger dans des cas individuels.
« Nos utilisateurs doivent pouvoir travailler avec toutes les données en même temps, et nous développons des fonctionnalités qui leur permettent de modifier les données existantes ou de passer des données à la littérature ; nous considérons que notre rôle est d'aider les utilisateurs à trouver où concentrer leur attention », a déclaré Moritz.
Cette application personnalisée et efficace de l’IA, moins spectaculaire qu’un ami numérique mais presque certainement beaucoup plus viable, pourrait accélérer la science dans un certain nombre de domaines hautement techniques. Les investisseurs en ont pris note et ont financé un tour de financement de 11,3 millions de dollars. Tola Capital et Inovia Capital ont mené le tour, avec la participation de l’investisseur providentiel Mike Volpi.
Comme toute application d'IA, la technologie de Reliant est très gourmande en ressources de calcul, c'est pourquoi l'entreprise a acheté son propre matériel plutôt que de le louer à la carte auprès d'un des grands fournisseurs. Le fait de se doter de matériel en interne présente à la fois des risques et des avantages : vous devez rentabiliser ces machines coûteuses, mais vous avez la possibilité de résoudre le problème avec des ressources de calcul dédiées.
« Nous avons constaté qu’il est très difficile de donner une bonne réponse si vous disposez de peu de temps », explique Moritz. Par exemple, si un scientifique demande au système d’effectuer une nouvelle tâche d’extraction ou d’analyse sur une centaine d’articles. Cela peut être fait rapidement, ou bien, mais pas les deux, à moins qu’ils ne prédisent ce que les utilisateurs veulent. pourrait demandez et déterminez la réponse, ou quelque chose de similaire, à l'avance.
« Le problème, c'est que beaucoup de gens ont les mêmes questions, donc nous pouvons trouver les réponses avant qu'ils ne les posent, comme point de départ », a déclaré Bellemare, directeur scientifique de la start-up. « Nous pouvons distiller 100 pages de texte en quelque chose d'autre, ce n'est peut-être pas exactement ce que vous voulez, mais c'est plus facile à utiliser pour nous. »
Pensez-y de cette façon : si vous deviez extraire le sens d'un millier de romans, attendriez-vous que quelqu'un vous demande les noms des personnages pour les parcourir et les récupérer ? Ou feriez-vous simplement ce travail à l'avance (en même temps que des éléments tels que les lieux, les dates, les relations, etc.) en sachant que les données seraient probablement recherchées ? Certainement la deuxième option, si vous aviez la puissance de calcul nécessaire.
Cette pré-extraction donne également aux modèles le temps de résoudre les ambiguïtés et hypothèses inévitables rencontrées dans différents domaines scientifiques. Lorsqu'une mesure « indique » une autre, cela peut ne pas signifier la même chose dans le domaine pharmaceutique que dans celui de la pathologie ou des essais cliniques. De plus, les modèles linguistiques ont tendance à donner des résultats différents selon la manière dont on leur pose certaines questions. La tâche de Reliant a donc consisté à transformer l'ambiguïté en certitude — « et c'est quelque chose que vous ne pouvez faire que si vous êtes prêt à investir dans une science ou un domaine particulier », a noté Moritz.
En tant qu’entreprise, Reliant s’efforce en premier lieu de démontrer que la technologie est rentable avant de se lancer dans des projets plus ambitieux. « Pour réaliser des progrès intéressants, il faut avoir une vision d’ensemble, mais il faut aussi commencer par quelque chose de concret », a déclaré Moritz. « Du point de vue de la survie des startups, nous nous concentrons sur les entreprises à but lucratif, car elles nous donnent de l’argent pour payer nos GPU. Nous ne vendons pas nos produits à perte aux clients. »
On pourrait s’attendre à ce que l’entreprise subisse la pression de sociétés comme OpenAI et Anthropic, qui investissent massivement dans la gestion de tâches plus structurées comme la gestion de bases de données et le codage, ou de partenaires de mise en œuvre comme Cohere et Scale. Mais Bellemare est optimiste : « Nous construisons cela sur la base d’une vague de fond. Toute amélioration de notre pile technologique est excellente pour nous. Le LLM est l’un des huit grands modèles d’apprentissage automatique qui existent. Les autres sont entièrement notre propriété, créés de toutes pièces sur la base de données qui nous appartiennent. »
La transformation du secteur des biotechnologies et de la recherche en un secteur axé sur l’intelligence artificielle n’en est qu’à ses débuts et risque d’être assez inégale dans les années à venir. Mais Reliant semble avoir trouvé une base solide pour démarrer.
« Si vous voulez une solution à 95 % et que vous vous contentez de vous excuser auprès de l'un de vos clients de temps en temps, c'est parfait », a déclaré Moritz. « Nous sommes là pour les cas où la précision et la mémorisation sont vraiment importantes, et où les erreurs sont vraiment importantes. Et franchement, cela suffit, nous sommes heureux de laisser le reste à d'autres. »





