
De Tableau et Looker à PowerBI et au-delà, les outils de business intelligence (BI) ne manquent pas conçus pour aider les entreprises à extraire des informations de leurs vastes étendues de données. Mais un nouveau venu est arrivé sur la scène avec de nouvelles connaissances en matière de BI, destinées aux équipes de données plus « techniquement enclines ».
Fondée à Toronto, au Canada, en 2021, Evidence a émergé de la cohorte de startups de l’été 2021 de Y Combinator (YC) avec la promesse d’une alternative moderne aux acteurs historiques populaires de BI. En effet, même si de nombreux outils de BI partagent des caractéristiques clés, ils varient souvent en termes de OMS ils ciblent : certains proposent des flux de travail davantage basés sur le code pour l’ingestion de données, comme Looker de Google, d’autres proposent une interface basée sur le glisser-déposer qui s’adresse aux analystes de données moins techniques, et d’autres encore proposent un mélange des deux.
En plus de cela, les logiciels de BI se déclinent en une variété de versions propriétaires et open source, facteurs qui peuvent influencer les outils qu’une entreprise souhaite déployer.
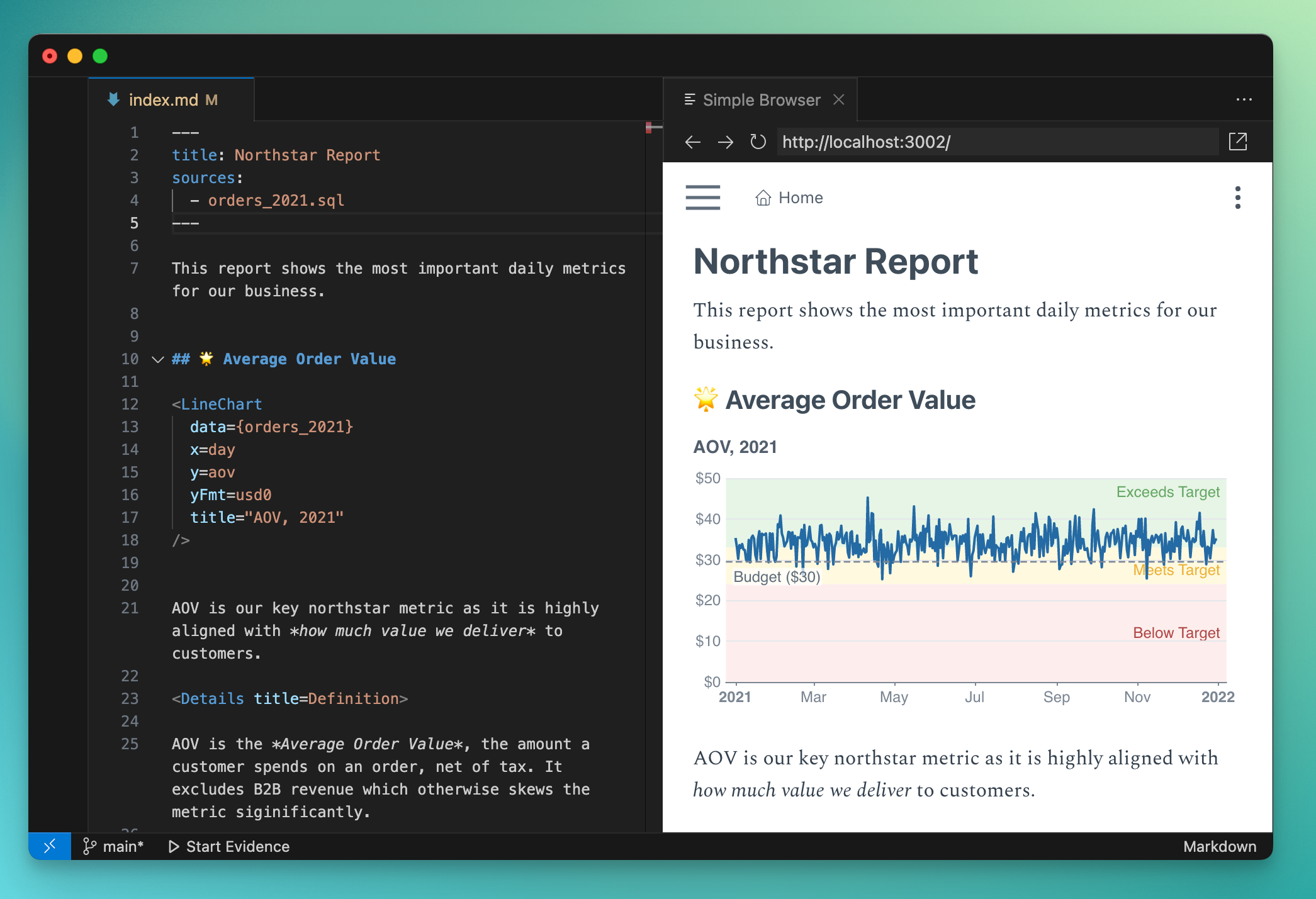
Evidence, pour sa part, aborde les choses d’un point de vue très basé sur le code, permettant aux équipes de créer des produits de données à l’aide de SQL et du markdown. De plus, il est entièrement open source, pour démarrer.
Cherchant à étendre son empreinte commerciale, Evidence a annoncé aujourd’hui avoir levé une tranche de financement de démarrage et ouvre son produit cloud premium aux entreprises qui n’ont pas les ressources nécessaires pour déployer et héberger elles-mêmes Evidence.
Supprimer le glisser-déposer
Les workflows BI par glisser-déposer ont leur place, dans la mesure où ils permettent aux équipes data de gérer et de manipuler plus facilement leurs données. Mais cela peut manquer de la sophistication et de la granularité offertes par des approches plus manuelles.
« Ce processus de création de rapports par glisser-déposer convient à de nombreuses équipes de données, mais il est très pénible pour les équipes de données plus techniques », a déclaré Sean Hughes, co-fondateur et COO d’Evidence à TechCrunch. « Il en résulte des produits de données extrêmement difficiles à utiliser pour les utilisateurs finaux et à gérer pour les équipes chargées des données. »
Dans Evidence, chaque étape, de la recherche de données à la définition des rapports, est réalisée à l’aide de code. Selon Hughes, c’est une préférence pour de nombreuses équipes de données modernes qui préfèrent fonctionner davantage comme des ingénieurs logiciels. Par exemple, cela prend en charge le contrôle de version et la gouvernance : les utilisateurs peuvent gérer l’ensemble de leur flux de travail et la collaboration d’équipe à l’aide de Git, et ils peuvent créer un historique complet et précis du projet. Cela signifie également qu’ils peuvent revisiter les anciennes versions d’un produit et couper/copier/coller et réutiliser l’ancien code.
« La plupart des outils de BI sont remplis de rapports anciens, défectueux et non pertinents, car il faut énormément de temps pour créer quelque chose, puis en déplacer des éléments ailleurs », a expliqué Hughes. « Du coup, on ne veut pas jeter les choses. Ce n’est pas le cas avec Evidence.
De plus, une approche basée sur le code soutient également les équipes dans leurs efforts plus larges d’intégration et de déploiement continus (CI/CD).
« Vous pouvez travailler sur une version de développement de votre projet tout en apportant des modifications, exécuter des tests sur ces modifications et publier les mises à jour en production avec une pull request », a expliqué Hughes.
Démarquage basé sur des preuves dans l’identifiant de l’utilisateur, avec aperçu en direct à droite Crédits images: Preuve
À certains égards, Evidence peut ressembler à un contre-courant ou à un « recul » contre le mouvement plus large du no-code/low-code, mais Hughes estime que son entreprise sert davantage d’« extension » à un mouvement distinct qui prend de l’ampleur dans le domaine de l’analyse. espace.
« Les équipes de données souhaitent de plus en plus travailler comme des ingénieurs logiciels et ont commencé à adopter des produits basés sur le code – et open source – dans leur pile de données », a déclaré Hughes.
Une analogie utilisée par Hughes pour souligner ce point est celle de Squarespace, le géant d’un milliard de dollars qui aide presque tout le monde à créer son propre site Web. Bien sûr, cela sert un objectif à des millions de personnes, mais ce n’est pas adapté à tous les scénarios.
« Les outils de reporting sans code/low code fonctionnent bien pour beaucoup de gens, mais ils sont beaucoup trop limités pour les équipes de données plus techniques », a déclaré Hughes. « Ce serait comme confier Squarespace à une équipe de développement Web front-end. Squarespace fonctionne très bien pour un segment d’utilisateurs qui ont besoin de créer un site Web simple, mais un développeur professionnel voudra et devra faire bien plus. Nous nous concentrons sur la création de quelque chose d’incroyable pour les équipes de données techniquement enclines qui ont besoin d’aller au-delà de ce qui est possible dans un outil no-code/low-code.
L’open source est également un argument de vente majeur par rapport aux poids lourds de l’industrie tels que Looker ou Tableau, avec des sociétés comme Lightdash, Metabase et Apache Superset (qui possède également une entité commerciale soutenue par du capital-risque) se disputant l’affection des équipes de données. Selon Hughes, la plupart de ces outils ressemblent beaucoup à Tableau ou Looker, sauf qu’ils peuvent être auto-hébergés. Il s’agit bien sûr d’un énorme avantage en soi, car les entreprises peuvent conserver le contrôle total de leurs données, mais c’est cette approche open source. combiné avec un flux de travail basé sur du code qui, espère Evidence, séduira les entreprises du monde entier.
Après une période prolongée en mode d’accès anticipé, Evidence étend également désormais l’accès à son service cloud à un public plus large dans le cadre d’un nouveau programme sur invitation, soutenu par un financement de démarrage de 2,1 millions de dollars de A Capital, Y Combinator, SV Angel. , et une foule d’investisseurs providentiels.
« Toutes les personnes figurant sur notre liste d’attente actuelle auront accès à Evidence Cloud », a déclaré Hughes. «Nous passons d’une liste d’attente à un système sur invitation uniquement, auquel toute personne ayant une invitation aura accès. Les invitations peuvent être reçues des clients actuels d’Evidence Cloud ou directement d’un membre de l’équipe Evidence.
Le plan cloud comprend un niveau de démarrage gratuit qui comprend jusqu’à 5 comptes de « spectateur » (c’est-à-dire d’utilisateurs finaux), ainsi qu’un plan d’équipe coûtant 500 $ par mois qui comprend jusqu’à 50 comptes de spectateur. Des exigences supplémentaires au niveau de l’entreprise, telles que l’authentification unique (SSO) et davantage de comptes de spectateur, peuvent également être prises en charge dans le cadre d’un plan personnalisable.




